


🗺️ Map
key, value 쌍으로 저장하고 관리하는 자료구조
인덱스로 값에 접근하는 리스트, 배열과는 다르게 Map을 사용하면 개발자가 지정하는 key로 값에 접근이 가능하다.
Map은 그 내부 구현 방식에 따라 'HashMap', 'TreeMap', 'LinkedHashMap' 등으로 나뉜다.

장점
- 빠른 데이터 검색
- 데이터 검색과 조회가 빠르다. 키를 통해 바로 값으로 접근할 수 있기때문
- 키 기반 데이터 관리
- 키로 고유 식별자를 부여하여 데이터를 관리할 때 적합함. ex) Key == 학생 ID, Value == 학생정보
단점
- 메모리 사용량 증가
- 키 관리의 복잡성
- 키의 고유성을 유지해야한다. 동일한 키를 사용해 삽입하면 기존 값이 덮어씌워짐
주요 메서드
- put(key, value): 지정된 키와 값으로 맵에 데이터를 추가.
- get(key): 지정된 키에 해당하는 값을 반환.
- remove(key): 지정된 키에 해당하는 데이터를 제거.
- containsKey(key): 지정된 키가 맵에 존재하는지 확인.
Java에서 Key-value 쌍 저장 자료구조는 여러가지가 있다.
하나씩 살펴보자
1. HashMap
HashMap은 해싱(Hashing)을 사용하기 때문에 많은 양의 데이터를 검색할 때 뛰어난 성능을 보인다.
해싱(Hashing)이란??
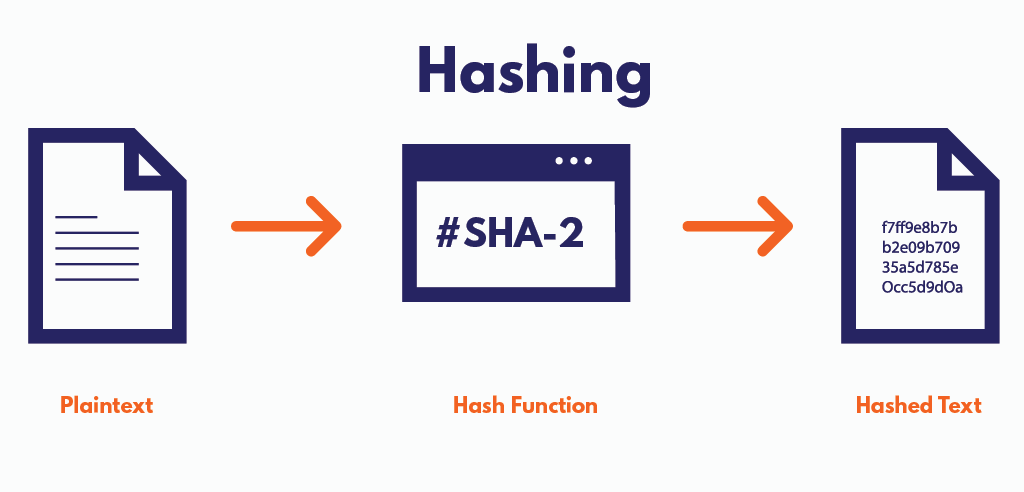
해싱(Hashing)은 입력값에 수학적 알고리즘(해시 함수)을 적용하여 고정된 크기의 문자열을 출력하는 과정이다.
- 메시지 다이제스트라고도 부름
- 주로 데이터 무결성, 효율적인 데이터 관리를 위해 사용된다.
해시함수는 임의의 길이를 갖는 임의의 데이터를 입력받아 고정된 길이의 데이터로 매핑하는 단방향 함수를 말한다.
입력값의 길이가 달라도 출력값은 언제나 고정된 길이의 비트열로 반환되고, 각 입력값에 고유한 출력값을 보장.
단방향 함수이기때문에 역으로 입력값을 산출할 수 없다.
또한 좋은 해시 함수는 효율적이고 다른 입력이 동일한 해시를 생성하는 것을 거의 불가능하게 한다.
이런 특성 때문에 해시를 데이터 비교 및 무결성에 안전하게 사용할 수 있다.
대표적으로 사용되는 해시 함수들
- 암호화 해시 함수(Cryptographic Hash Functions)
- 비밀번호 보관, 디지털 서명 등 보안 관련 용도로 사용되는 해시 함수.
- 대표적으로 SHA-256, SHA-3, MD5
- 비암호화 해시 함수(Non-cryptographic Hash Functions)
- 데이터 인덱싱 또는 해시 테이블과 같이 보안보다 효율이 필요할 때 사용되는 해시 함수.
- 대표적으로 MurmurHash, CityHash
그럼 이 해싱을 HashMap에서 어떻게 활용할까??
바로 아래의 그림처럼 key를 해싱해서 나온 출력값이 value의 index로 활용하는 것이다.

HashMap의 핵심 원리
'해싱 함수(Hashing Functoin)'는 키(key)를 받아서
정수값인 '해시코드(Hashcode)'를 반환하고,
반환된 해시코드는 Hash 배열의 각 요소인 '버킷(Bucket)'의 인덱스가 된다.
키(key)를 주면 해싱 함수에 의해 해시코드로 변환되고, 해당 해시코드는 배열의 각 요소인 버킷의 인덱스 역할을 한다.
해당 버킷을 찾아가면 값을 삽입 및 조회할 수 있다.
특징
- 키 기반의 빠른 액세스 : 키를 사용하여 값을 빠르게 검색하거나 수정할 수 있다.
- 순서를 보장하지 않음 : 'HashMap' 은 내부적으로 키의 순서를 보장하지 않는다.
- 키의 중복 불가 : 같은 키를 중복해서 사용할 수 없다. 이미 존재하는 키에 대해 값을 저장하면 기존 값이 덮어씌워진다.
- null 키와 값 : 'HashMap'은 null 키와 null 값을 저장할 수 있다. 하지만 키는 중복이 불가하므로 null 키는 하나만 저장될 수 있다.
- 키 기반의 유연성 : 어떤 객체든 키로 사용할 수 있다.
- 해싱 충돌 : 두 개 이상의 키가 동일한 해시 코드를 가질 때 충돌이 발생한다. 이는 성능 저하를 초래할 수 있다.
근데 아까 해시함수는 각 입력값에 고유한 출력값을 가진다고 하지 않았나?? 왜 충돌이 발생하지?? 라고 생각할 수 있다.
하지만 함수가 완벽하지 않으므로 키가 너무 많이 입력되거나 버킷의 수 이상으로 입력이 들어올 때 서로 다른 키가 동일한 해시코드를 생성할 가능성이 존재한다.
따라서, 충돌을 처리하기 위해 여러 방법이 고안되었다.
해싱 충돌 해결방법
1. 체이닝 (Chaining)
이 방법에서 각 버킷은 연결리스트로 구현된다.
충돌이 발생하면, 해당 버킷의 연결리스트에 새로운 키-값 쌍을 추가한다.
구현이 간단하고, 메모리 할당이 동적으로 이루어지는 방법이다.
2. 개방 주소법 (Open Addressing)
충돌이 발생하면, 다른 버킷의 위치를 찾아 삽입을 시도한다.
다른 위치를 찾는 과정은 또 여러 방법으로 나뉜다.
- 선형조사 - 초기 위치에서 일정 간격으로 버킷을 조사하여 빈 위치를 찾는다.
- 제곱조사 - 충돌 발생 시 제곱만큼 떨어진 위치를 조사한다.
- 이중해싱 - 두번째 해시 함수를 사용하여 버킷 위치를 찾는다.
3. 재해싱 (Rehashing)
해시 테이블이 가득 차거나 충돌이 너무 많이 발생할 경우, 해시 테이블의 크기를 늘리고 모든 키-값 쌍을 새로운 크기에 맞게 재삽입
이 방법은 메모리 사용량을 늘리는 대신 충돌을 줄이고 성능을 향상시키는 데 효과적이다.
언제 사용하면 좋을까
데이터의 순서가 중요하지 않고, 키를 기반으로 빠른 데이터 액세스가 필요할 때 사용하면 좋다.
또한 어떤 객체든 키로 사용할 수 있기때문에 인덱스가 아니라 다른 키로 저장하고 싶을때 사용해도 좋은 것 같다.
🍒 사용 예제
import java.util.HashMap;
public class HashMapExample {
public static void main(String[] args) {
// HashMap 생성
HashMap<String, String> map = new HashMap<>();
// 데이터 추가
map.put("key1", "value1");
map.put("key2", "value2");
map.put("key3", "value3");
// 데이터 조회
System.out.println("key1의 값: " + map.get("key1")); // 출력: value1
// 데이터 수정
map.put("key1", "new_value1");
System.out.println("수정된 key1의 값: " + map.get("key1")); // 출력: new_value1
// 데이터 삭제
map.remove("key2");
System.out.println("key2 삭제 후: " + map.get("key2")); // 출력: null
// HashMap 크기 확인
System.out.println("HashMap 크기: " + map.size()); // 출력: 2
// 키 존재 여부 확인
System.out.println("key3 존재 여부: " + map.containsKey("key3")); // 출력: true
// 값 존재 여부 확인
System.out.println("value3 존재 여부: " + map.containsValue("value3")); // 출력: true
// 모든 키 출력
System.out.println("모든 키: " + map.keySet()); // 출력: [key1, key3]
// 모든 값 출력
System.out.println("모든 값: " + map.values()); // 출력: [new_value1, value3]
// 모든 키-값 쌍 출력
System.out.println("모든 키-값 쌍: " + map.entrySet()); // 출력: [key1=new_value1, key3=value3]
// HashMap 비우기
map.clear();
System.out.println("HashMap 비운 후 크기: " + map.size()); // 출력: 0
}
}
반복문을 이용한 HashMap 순회
import java.util.HashMap;
import java.util.Map;
public class HashMapIterationExample {
public static void main(String[] args) {
HashMap<String, String> map = new HashMap<>();
map.put("key1", "value1");
map.put("key2", "value2");
map.put("key3", "value3");
// 키를 사용한 순회
for (String key : map.keySet()) {
System.out.println("Key: " + key + ", Value: " + map.get(key));
}
// 키-값 쌍을 사용한 순회
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println("Key: " + entry.getKey() + ", Value: " + entry.getValue());
}
// 값만 순회
for (String value : map.values()) {
System.out.println("Value: " + value);
}
}
}
해시테이블(Hashtable)과의 차이점
해시테이블은 일반적인 컴퓨터 과학의 자료구조 원칙이다.
해시맵은 해시테이블의 원칙을 구체적으로 구현한 클래스나 자료구조라고 인식하면 될 것같다.
따라서 작동원리는 완전히 똑같다.
근데 Java에는 컬렉션 프레임워크가 만들어지기 전부터 존재하던 Hashtable 클래스가 있긴하다.
Hashtable, HashMap 둘 다 해시테이블이라는 자료구조를 바탕으로 만들어진 클래스이지만 약간의 차이가 존재한다.
호환을 위해 남겨두었지만 가능하면 HashMap을 사용하는 것을 추천한다고 한다.
차이점
- Thread-safe 여부
- Hashtable은 Thread-safe하고, HashMap은 Thread-safe하지 않다는 특징을 가지고 있다.
- Null 값 허용 여부
- Hashtable은 key에 null을 허용하지 않지만, HashMap은 key에 null을 허용한다.
- Enumeration 여부
- Hashtable은 not fail-fast Enumeration을 제공하지만, HashMap은 Enumeration을 제공하지 않는다.
- HashMap은 보조해시를 사용하기때문에 보조 해시 함수를 사용하지 않는 Hashtable에 비하여 해시 충돌이 덜 발생할 수 있다.
- HashMap은 개선이 지속적으로 이루어지고 있음
2. LinkedHashMap
- 입력 순서를 유지하는 HashMap의 확장 버전
- 삽입된 순서대로 데이터를 저장
3. TreeMap
TreeMap은 HashMap과 마찬가지로 키-값 쌍을 저장하는 자료구조이지만,
키를 기준으로 자동으로 정렬된다는 점이 다르다.
TreeMap은 레드-블랙 트리(Red-Black Tree)라는 자가 균형 이진 탐색 트리를 기반으로 구현되어 있다.
TreeMap과 HashMap의 주요 차이점
- 정렬: TreeMap은 키를 기준으로 자연 순서(natural order) 또는 지정된 Comparator에 따라 정렬된다. 반면 HashMap은 순서를 보장하지 않는다.
- 성능: HashMap은 일반적으로 O(1) 시간 복잡도로 데이터를 조회/삽입/삭제할 수 있지만, TreeMap은 O(log n) 시간 복잡도를 가진다.
- 널(Null) 허용: HashMap은 키와 값 모두 null을 허용하지만, TreeMap은 키로 null을 허용하지 않는다.
단순 조회/삽입/삭제가 중요한 부분은 HashMap, key가 정렬된 순서를 유지해야 하거나 범위 검색이 필요하면 TreeMap!
🍒 사용 예제
기본적으로 HashMap에서 썼던거 다 쓸 수 있다.
그런데 정렬된 순서를 유지하기 때문에 몇가지 메서드가 추가되었다.
TreeMap만의 추가 기능
- firstKey(): 가장 작은(첫 번째) 키를 반환.
- lastKey(): 가장 큰(마지막) 키를 반환.
- lowerKey(K key): 주어진 키보다 작은 키 중 가장 큰 키를 반환.
- higherKey(K key): 주어진 키보다 큰 키 중 가장 작은 키를 반환.
- floorKey(K key): 주어진 키보다 작거나 같은 키 중 가장 큰 키를 반환.
- ceilingKey(K key): 주어진 키보다 크거나 같은 키 중 가장 작은 키를 반환.
import java.util.TreeMap;
public class TreeMapSpecialMethods {
public static void main(String[] args) {
TreeMap<Integer, String> map = new TreeMap<>();
map.put(10, "value10");
map.put(20, "value20");
map.put(30, "value30");
map.put(40, "value40");
// 첫 번째 키
System.out.println("첫 번째 키: " + map.firstKey()); // 출력: 10
// 마지막 키
System.out.println("마지막 키: " + map.lastKey()); // 출력: 40
// 25보다 작은 키 중 가장 큰 키
System.out.println("25보다 작은 키 중 가장 큰 키: " + map.lowerKey(25)); // 출력: 20
// 25보다 큰 키 중 가장 작은 키
System.out.println("25보다 큰 키 중 가장 작은 키: " + map.higherKey(25)); // 출력: 30
// 25보다 작거나 같은 키 중 가장 큰 키
System.out.println("25보다 작거나 같은 키 중 가장 큰 키: " + map.floorKey(25)); // 출력: 20
// 25보다 크거나 같은 키 중 가장 작은 키
System.out.println("25보다 크거나 같은 키 중 가장 작은 키: " + map.ceilingKey(25)); // 출력: 30
}
}
4. Hashtable
- HashMap과 유사하지만, 동기화가 지원됨
- 키와 값으로 null이 허용되지 않음
🍒 사용 예제
Hashtable<String, String> table = new Hashtable<>();
table.put("key1", "value1");
table.put("key2", "value2");
5. ConcurrentHashMap
- 멀티스레드 환경에서 안전하게 사용할 수 있도록 설계된 HashMap의 동기화 버전
- 동시성을 높이기 위해 내부적으로 세분화된 락을 사용
🍒 사용 예제
ConcurrentHashMap<String, String> concurrentMap = new ConcurrentHashMap<>();
concurrentMap.put("key1", "value1");
concurrentMap.put("key2", "value2");
6. Properties
- key와 value 모두 문자열 타입
- 주로 설정 파일이나 환경 변수를 관리할 때 사용됨
🍒 사용 예제
Properties properties = new Properties();
properties.setProperty("key1", "value1");
properties.setProperty("key2", "value2");
주요 선택 기준
- 빠른 검색 및 삽입: HashMap, ConcurrentHashMap
- 입력 순서 유지: LinkedHashMap
- 정렬 필요: TreeMap
- 멀티스레드 환경: ConcurrentHashMap, Hashtable
- 설정 파일 관리: Properties
'알고리즘공부 > 자료구조' 카테고리의 다른 글
| [자료구조] 배열 (Array) (0) | 2025.01.31 |
|---|---|
| [자료구조] Set (0) | 2025.01.27 |
| [자료구조] Heap (힙) (0) | 2025.01.21 |
| [자료구조] 그래프, dfs, bfs (0) | 2025.01.21 |
| [자료구조] 트라이 (trie) (0) | 2025.01.20 |